



The price of flagship LLMs models can easily be 15 to 50 times the price of their smaller and weaker siblings. As a reference, gpt-4o costs $5 / 1 M input tokens meanwhile gpt-4o-mini costs $0.150 / 1 M input tokens1. We can ask the following question: Can we route between the two models on demand to minimize costs while maintaining performance? In other words, when our application is given easier tasks, we want to use the cheaper model and when given complex reasoning tasks we want to use the bigger model. We can understand this by looking at the next figure, which represents the performance on MT Bench2 of a router that randomly routes between two models.
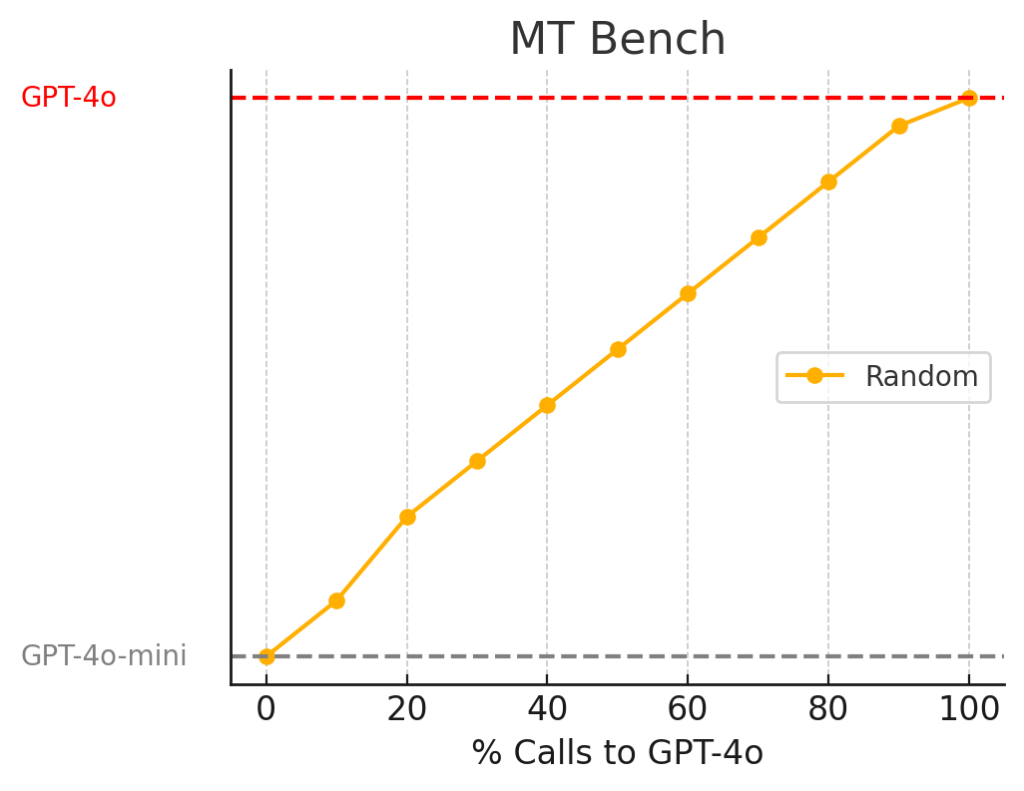
This is where RouteLLM3: An Open-Source Framework for Cost-Effective LLM Routing4 developed by LLMSys Org together with AniyScale comes into play where researchers trained different types of LLM Classifiers for routing and showed that you can get 95% of GPT-4o performance while reducing the costs by 85%.
To use it in our project:
1. Install it from PyPI: pip install “routellm[serve,eval]”
2. Replace your existing OpenAI client with RouteLLM Controller as shown in the example, here we are routing using matrix factorization method which recommended by the authors.
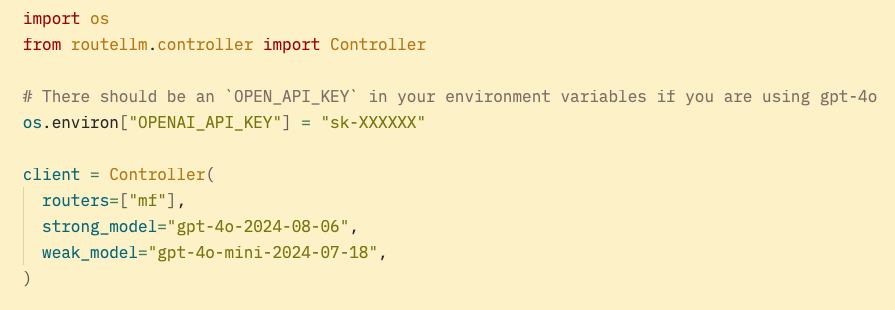
As simple as that get 85% costs reduction.